
Hallo Gruppe,
ich habe hier einen Server im RZ (komme also physisch nicht ran), der nach "etwas" (sagen wir mal halbe Stunde) Laufzeit den reboot nicht schafft. Mir scheint, er bleibt im shutdown hängen. Wie debuggt man das nun?
In den Logfiles ist nichts auffällig und der letzte Eintrag : in der Art "journald beendet sich". Klar nun kann nichts mehr geloggt werden. Ich kann dann einen hard reset (über die USV) auslösen und die Kiste kommt wieder. Mache ich dann recht fix (in den nächsten paar Minuten) einen reboot, läuft der sauber durch. Warte ich mehr als ca. ne halbe Stunde, habe ich das Problem wieder.
Also KVM dran. Der bringt erst Bild nach reboot und kann nur für eine begrenzte Zeit "gemietet" werden. Durch den weiß ich, dass das mit reboot kurz nach Hochfahren scheinbar immer klappt 😉 wollte ja schnell sein und das reproduzieren. Aber einmal konnte ich nen screenshot machen, wo er nach knapp 40min Laufzeit eben nicht wieder hochfuhr (irgendwas hat mich wohl zwischendurch abgelenkt).
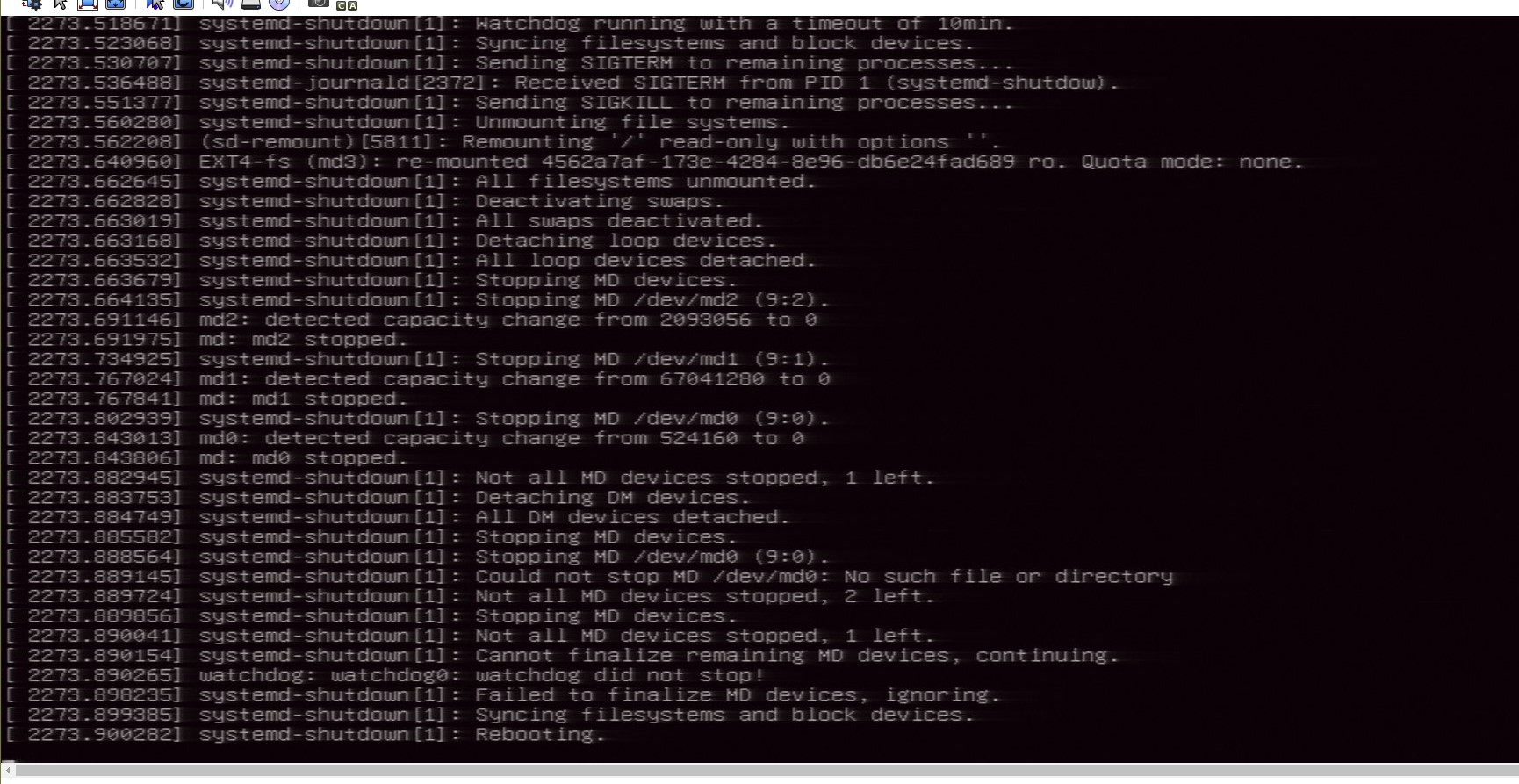
Habt Ihr jetzt Tipps für mich, was die Kiste am reboot hindert? Ich finde ja die md-Meldungen (siehe screenshot) seltsam.
root@kiste /etc # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS zram0 252:0 0 0B 0 disk nvme0n1 259:0 0 476.9G 0 disk ├─nvme0n1p1 259:2 0 256M 0 part │ └─md0 9:0 0 255.9M 0 raid1 /boot/efi ├─nvme0n1p2 259:3 0 32G 0 part │ └─md1 9:1 0 32G 0 raid1 [SWAP] ├─nvme0n1p3 259:4 0 1G 0 part │ └─md2 9:2 0 1022M 0 raid1 /boot └─nvme0n1p4 259:7 0 443.7G 0 part └─md3 9:3 0 443.6G 0 raid1 / nvme1n1 259:1 0 476.9G 0 disk ├─nvme1n1p1 259:5 0 256M 0 part │ └─md0 9:0 0 255.9M 0 raid1 /boot/efi ├─nvme1n1p2 259:6 0 32G 0 part │ └─md1 9:1 0 32G 0 raid1 [SWAP] ├─nvme1n1p3 259:8 0 1G 0 part │ └─md2 9:2 0 1022M 0 raid1 /boot └─nvme1n1p4 259:9 0 443.7G 0 part └─md3 9:3 0 443.6G 0 raid1 /
Irgendwo habe ich ohne Erklärung die Behauptung gelesen EFI und md ...
Mit freundlichen Grüßen / Kind regards Ronny Seffner
{kind=link}

Hallo,
On Fri, Dec 15, 2023 at 05:39:30PM +0100, ronny@seffner.de wrote:
Habt Ihr jetzt Tipps für mich, was die Kiste am reboot hindert? Ich finde ja die md-Meldungen (siehe screenshot) seltsam.
Die md Meldungen sehen für mich ok aus.
root@kiste /etc # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS ... └─nvme0n1p4 259:7 0 443.7G 0 part └─md3 9:3 0 443.6G 0 raid1 / ... └─nvme1n1p4 259:9 0 443.7G 0 part └─md3 9:3 0 443.6G 0 raid1 /
Das einzige was er nicht umounten kann (weil in use) ist md3 eg das rootfs. Das hat er aber vorher ro gemounted. Und er scheint auch die eigentlich reboot Sequenz einzuleiten. Das Problem liegt denke ich woanders.
Grüsse Andreas
Hallo Gruppe, Hallo Andreas,
ich sah halt nur die md-Meldungen und in Zusammenhang mit "never shutdown" dann eine angebliche md vs. EFI Unverträglichkeit. Hab mich da wohl irritieren lassen.
Das Problem liegt denke ich woanders.
Ich habe jetzt "watchdog" installiert. So wie ich das verstehe, schreibt das ein "alive" alle 60 Sekunden in den kernelspace, und wenn das mal nicht kommt, geht der kernel in den reboot. Bei einem gewünschten reboot hat mir das schon geholfen - empirisch ist das aber noch nicht. Vor allem aber bringt mich das der Ursache ja nicht näher.
Mit freundlichen Grüßen / Kind regards Ronny Seffner

Am Freitag, dem 15.12.2023 um 17:39 +0100 schrieb ronny@seffner.de:
ich habe hier einen Server im RZ (komme also physisch nicht ran), der nach "etwas" (sagen wir mal halbe Stunde) Laufzeit den reboot nicht schafft. Mir scheint, er bleibt im shutdown hängen.
Ich habe auch ein paar Systeme hier, bei denen das passiert, teilweise auch reproduzierbar. Die Logs geben gar nichts her. Ich mutmaße, dass das irgendwie mit den C-States im Zusammenhang steht und vielleicht durch andere Einstellungen im BIOS auch "gefixt" werden könnte. Bisher fehlt mir die Zeit dazu, dass auszutesten.
Das ist aber nur ein Bauchgefühl und ich kann völlig daneben liegen.
Gruß, Daniel
lug-dd@mailman.schlittermann.de
-
 Andreas Fett
Andreas Fett -
 Daniel Leidert
Daniel Leidert -
 ronny@seffner.de
ronny@seffner.de